搜索到
158
篇与
香蕉你个不呐呐
的结果
-

-
产品经理和项目经理如何进行边界划分 产品经理(PM)和项目经理(PMO)是两个在很多公司中都非常关键的角色,它们的职责和工作内容有许多交集,但也存在显著的区别。为了避免职能重叠,明确两者的边界非常重要。下面是它们在岗位职责上的一些主要区别和边界划分:1. 核心职责的区别产品经理(Product Manager,PM)职责: 产品经理的主要职责是定义产品的功能、特性、用户需求和市场定位。PM关注的是“做什么”和“为什么做”。工作重点:产品规划与战略: 确定产品的长期发展方向与目标,分析市场需求,制定产品路线图。需求管理: 收集、分析和优先排序用户需求和业务需求,转化为产品功能。用户体验: 聚焦用户需求,确保产品的用户体验良好。市场调研: 了解市场趋势,研究竞争产品,确保产品的差异化和市场竞争力。产品生命周期管理: 从产品的立项到发布、迭代更新和最终淘汰的全过程管理。项目经理(Project Manager,PMO)职责: 项目经理的主要职责是确保项目按照计划高效执行,确保“如何做”和“何时做”。工作重点:项目规划: 制定详细的项目计划,包括时间表、资源分配、预算等。进度跟踪: 负责监控项目进度,确保项目按时交付。团队协调: 协调各方资源(如研发、设计、测试等),确保各项任务按时完成。风险管理: 识别潜在的风险并提出解决方案。沟通管理: 确保项目团队和相关方的沟通顺畅,及时向高层报告项目进展。2. 职能划分产品经理:主要负责产品方向、功能设计、需求定义和市场反馈等,更多的是战略性的角色,专注于产品的长远规划和价值创造。项目经理:主要负责项目的执行、交付和管理,是更具执行力的角色,专注于确保项目按照时间、预算和质量要求交付。3. 具体职责对比职责项产品经理(PM)项目经理(PMO)目标确保产品满足市场和用户需求,推动产品价值确保项目按时按预算完成,达成预定目标主要任务定义产品战略、功能、用户需求制定项目计划、管理进度、风险和资源决策产品功能、特性和用户体验的决策项目的执行、进度、风险管理的决策输出产品路线图、需求文档、用户故事项目计划、进度报告、风险评估报告工作对象用户、市场、产品团队项目团队、资源方、上级管理层时间维度长期(产品生命周期管理)短期(项目周期内的执行和管理)关注点产品的创新性和市场定位项目的进度、成本和质量4. 工作交集虽然两者的职能有所不同,但在实际工作中,产品经理和项目经理的工作常常有交集,特别是在产品开发阶段:需求到执行的过渡: 产品经理负责定义产品需求,并确定优先级,项目经理则负责将这些需求转化为具体的项目任务,确保需求得到有效实现。跨部门协作: 产品经理需要与项目经理紧密合作,确保产品开发团队(如技术、设计、测试等)在规定的时间内完成任务,同时确保项目经理能够根据产品需求调整进度安排。沟通与反馈: 产品经理需要从项目经理那里获取项目进度信息,调整产品需求的优先级,项目经理也需要向产品经理反馈项目进度和潜在的风险。5. 明确边界的方式为了使产品经理和项目经理的角色边界更加清晰,可以从以下几个方面进行划分:角色定义与责任清单: 明确各自的工作职责和目标,确保没有职责重叠。协作流程: 确定如何在产品开发过程中进行协作。例如,产品经理负责需求的制定和评审,项目经理负责执行、进度控制。沟通机制: 建立定期的跨部门沟通机制,确保信息流畅,避免重复工作或误解。文档管理: 产品经理专注于产品文档(需求文档、用户故事等),项目经理专注于项目文档(项目计划、进度表等)。总结产品经理:更多关注产品的战略方向、市场需求、功能设计和产品定位,属于产品的“老板”,确保产品创造价值。项目经理:更多关注如何实现产品的目标,负责项目的时间、成本、质量和资源管理,确保产品按计划交付。通过明确两者的职责分工,可以有效避免职能重叠,提高团队协作效率,推动产品的成功落地。
-
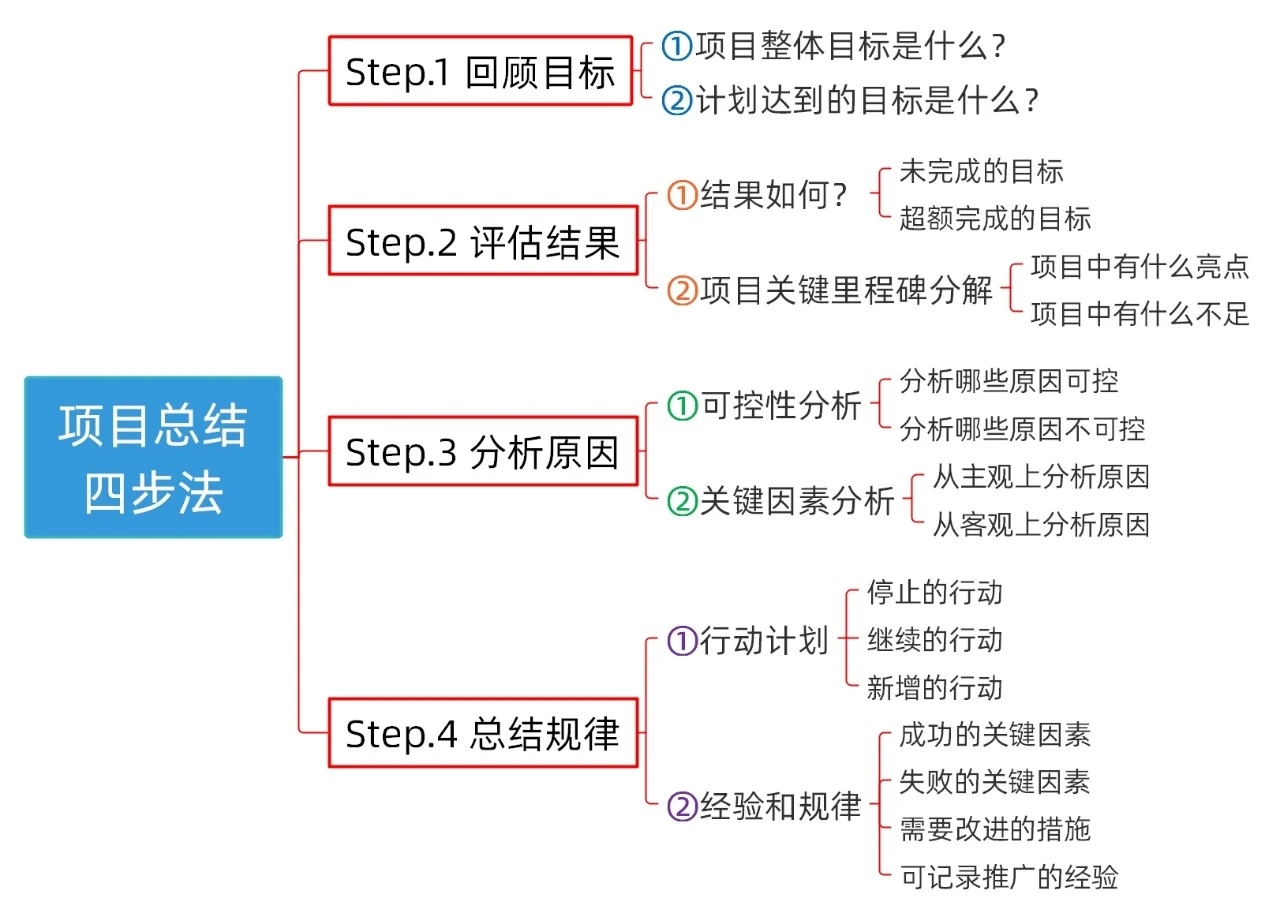
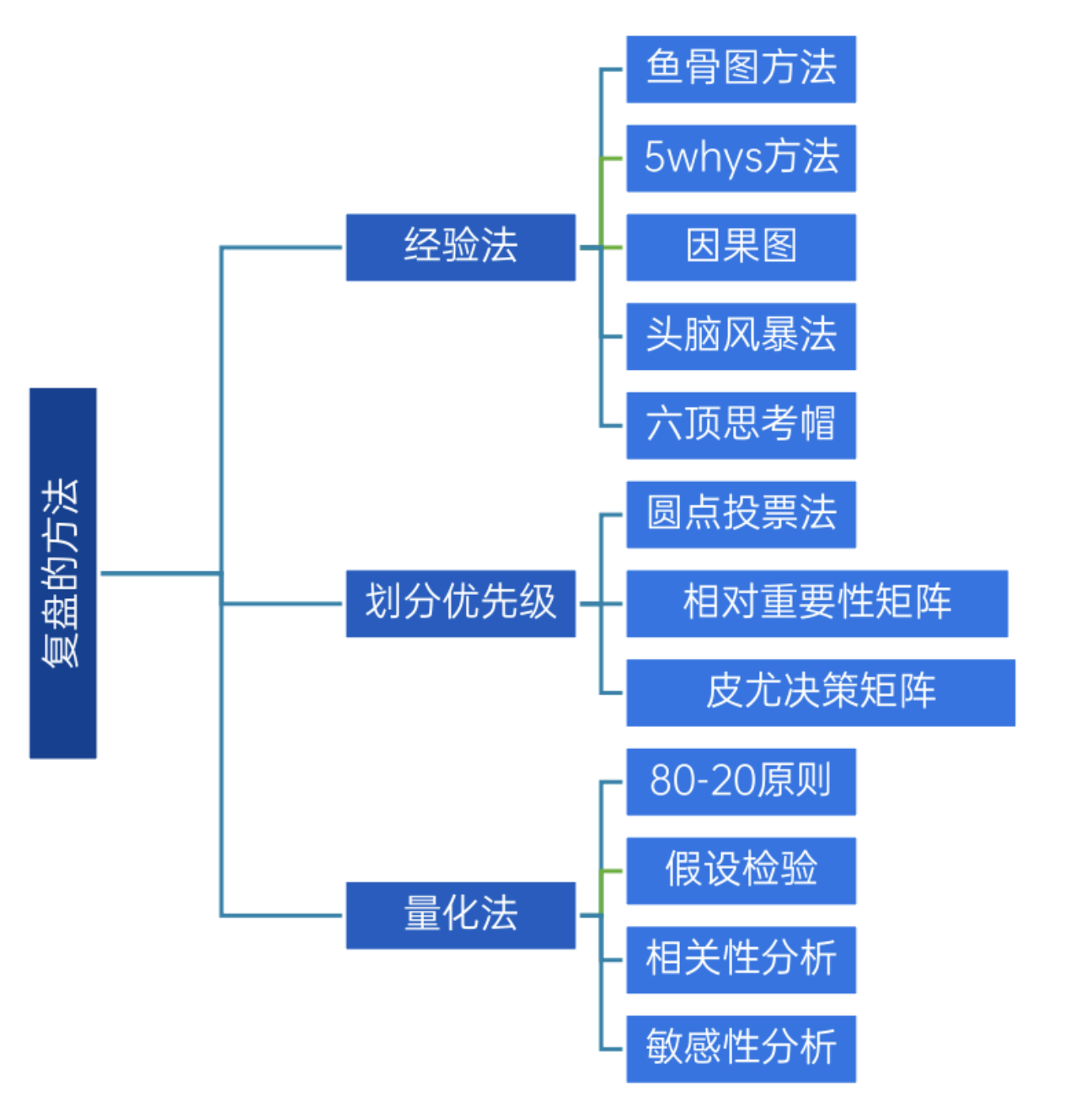
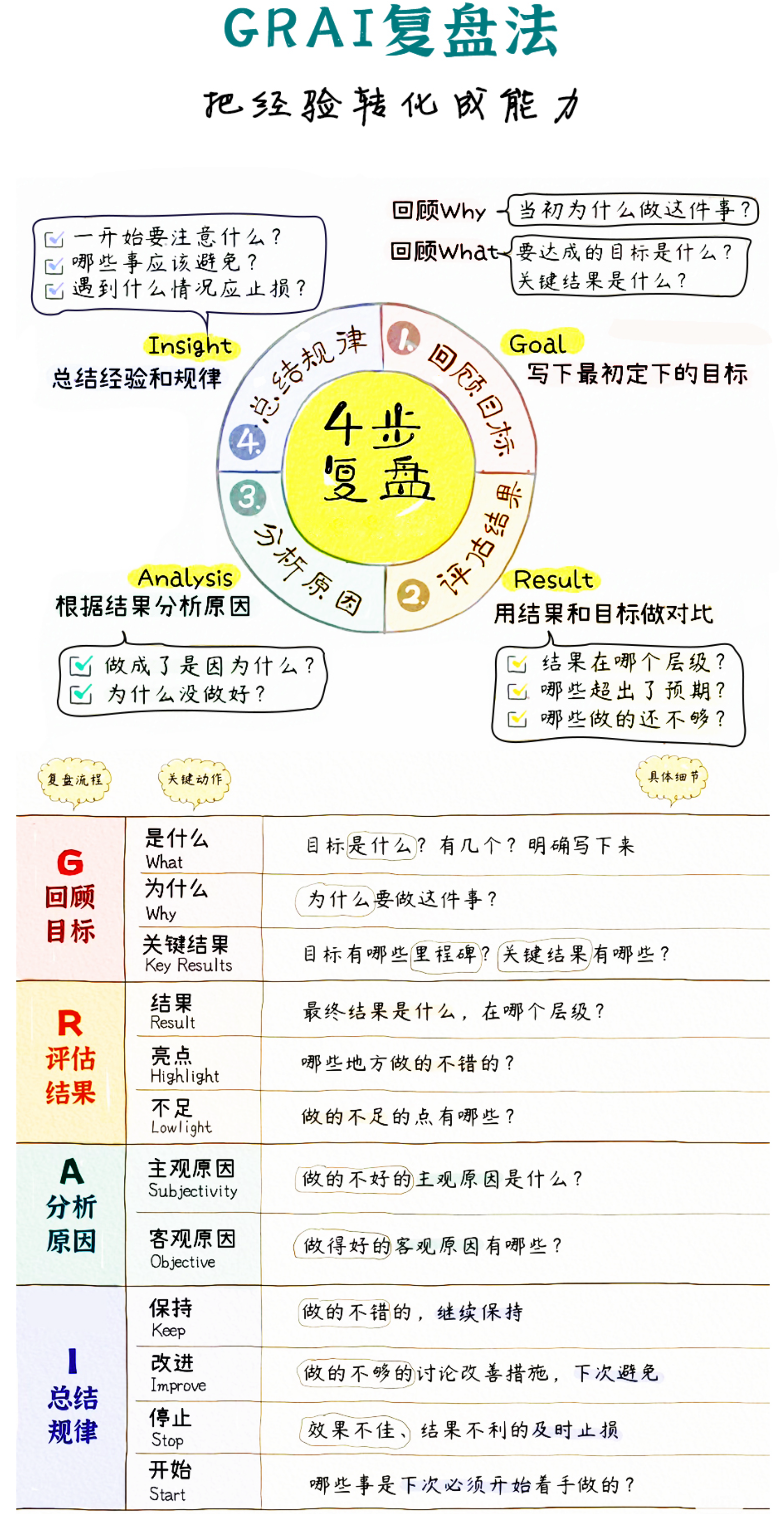
改进 需求质量保障通过需求评审、发布前演示评审全面保障需求一次做对、做好。需求评审(一次做对)利益相关方参加评审:需求提出人、相关研发人员、业务专家等利益相关方均参加评审,保证大家对需求达成一致评审问题闭环管理:评审问题得到有效解决,达到评审目的发布前演示评审(一次做好)需求利益相关方评审:从实际使用的角度,确认实现的功能是否符合预期复盘总结推诿责任:都是别人的错,我没问题众说纷坛:对原因无法达成一致意见流程正义:该做的都做了原因太多:找不到突破点屡教不改:以为找到了根因,但问题还会重现缺乏闭环:措施没有落地固化复盘方法从感觉到事实,从形容词到量词定性分析定量分析原因优先级直接原因或根本原因开发人员新进入项目,对业务不熟项目组有多少人?有多少是新进入?4直接原因使用公司级代码编写规范,不够细致什么叫不够细致呢?这种形容词能否用数字刻画?1根本原因需求理解不充分不准确不充分,不准确有无数字可以证明呢2根本原因人员变动频率高单因素方差分析:缺陷密度和人员经验有关3根本原因刻画事实,而非主观判断用数据刻画事实量化分析的方法案例交通事故的80-20分析对原因的分80-20分布分析多层80-20分析定位原因如果不服从80-20分布怎么办呢案例相关性分析综合案例案例1:工作量偏差率比较大某客户存在的现象是:项目成本偏差大。案例1:返工工作量占比的分布分析案例1:对原因进行汇总排序分析问题复盘的可选流程原因的分类:PPT技术分析管理分析原因反洗的注意事项先事实,再原因:把问题定义清晰,再去找原因,不要南辕北辙,方向有误。先感性,再理性:基于经验有个大概的假设,再通过数据验证及假设。先细化,再量化:把问题拆分细化,定位问题,通过数据刻画事实。先技术,再管理:先考虑技术上的原因,再考虑管理上的原因,两条线都要思考原因。先广度,再深度;先全面思考原因,避免思维盲点,再找到主要原因进行深挖。先体系,再个体:先找体系、流程、制度的问题,再说人员的问题。先自己,再他人:先讨论本作业环节的原因,再识别去其他环节的合作协同问题。先原因,再措施;找到原因后,再识别措施,不要不加分析就给出解决方案。先简单,再复杂:先从简单原因和易行着手,再从复杂的原因和高难度的措施着手。先纠正,再固化:先定义出来纠正措施,再思考如何将这些措施固化为习惯。先近期,再远期:先识别距离结果时间最近的影响因子,再识别时间较久的影响因子。养成定量思维的习惯
-
使用 APScheduler 来管理多个 Python 业务脚本 使用 APScheduler 来管理多个 Python 业务脚本的定时执行的详细示例和使用方法。 我们将使用一个简单的例子,然后逐步扩展到更复杂的情况。1. 安装 APScheduler:首先,你需要安装 APScheduler 库:pip3 install apscheduler2. 简单的例子 (单个任务):这个例子展示如何每分钟运行一个简单的函数:from apscheduler.schedulers.blocking import BlockingScheduler import time def my_job(): print("I'm working...") time.sleep(5) # 模拟任务执行时间 print("Job completed.") scheduler = BlockingScheduler() scheduler.add_job(my_job, 'interval', seconds=60) # 每分钟运行一次 scheduler.start()运行这个脚本,你会看到每分钟都会打印 "I'm working..." 和 "Job completed."。 BlockingScheduler 会阻塞主线程直到你手动停止它 (例如,使用 Ctrl+C)。3. 多个任务:你可以添加多个任务到同一个调度器中:from apscheduler.schedulers.blocking import BlockingScheduler import time def job1(): print("Job 1 is running...") time.sleep(2) print("Job 1 completed.") def job2(): print("Job 2 is running...") time.sleep(3) print("Job 2 completed.") scheduler = BlockingScheduler() scheduler.add_job(job1, 'interval', seconds=10) # 每 10 秒运行一次 scheduler.add_job(job2, 'cron', day_of_week='mon-fri', hour=10, minute=30) # 工作日 10:30 运行 scheduler.start()这个例子展示了如何使用不同的调度方式:interval (间隔时间) 和 cron (cron 表达式)。4. 使用不同的调度方式:APScheduler 支持多种调度方式:interval: 以固定的时间间隔运行任务。 参数包括 seconds, minutes, hours, days, weeks。cron: 使用 cron 表达式来指定任务运行的时间。 这提供了非常灵活的调度能力。 例如,'cron', day_of_week='mon-fri', hour=8, minute=0 表示工作日早上 8:00 运行。date: 在指定的时间点运行任务一次。其他: APScheduler 还支持其他调度方式,例如 trigger (自定义触发器)。5. 错误处理:在实际应用中,你的任务可能会失败。 你可以使用 try...except 块来处理异常:from apscheduler.schedulers.blocking import BlockingScheduler import time def my_job(): try: # 你的业务逻辑 print("Job is running...") # ... 可能出错的代码 ... 1 / 0 # 模拟一个错误 except Exception as e: print(f"Job failed: {e}") scheduler = BlockingScheduler() scheduler.add_job(my_job, 'interval', seconds=10) scheduler.start()6. 从外部文件导入任务:如果你的任务在不同的文件中,你可以从外部文件导入它们:# main.py from apscheduler.schedulers.blocking import BlockingScheduler import my_jobs scheduler = BlockingScheduler() scheduler.add_job(my_jobs.job1, 'interval', seconds=10) scheduler.add_job(my_jobs.job2, 'cron', day_of_week='mon-fri', hour=10, minute=30) scheduler.start() # my_jobs.py def job1(): print("Job 1 from external file") def job2(): print("Job 2 from external file")7. 停止调度器:你可以使用 scheduler.shutdown() 来优雅地停止调度器。8. 更高级的用法:APScheduler 还提供更高级的功能,例如:任务持久化: 将任务信息保存到数据库中,以便在调度器重启后恢复任务。作业存储: 使用不同的作业存储后端,例如数据库或文件系统。监听器: 添加监听器来监控任务的执行情况。记住将这些例子中的占位符函数替换成你实际的业务脚本函数。 根据你的业务脚本的复杂性和需求,选择合适的调度方式和错误处理机制。 如果你的任务之间存在依赖关系,你可能需要考虑使用更高级的调度功能或其他工具。
-
如何在生产环境中后台运行Gunicorn 本文细解释如何在生产环境中后台运行Gunicorn。 如何将 gunicorn --workers 3 --bind 0.0.0.0:9999 app:app 命令在后台稳定运行,并能够处理进程重启和优雅关闭等情况。直接使用 & 在后台运行是不够可靠的。我们需要借助进程监控工具来实现。常用的有两种:systemd(Linux系统推荐)和Supervisor(跨平台)。方法一:使用 systemd (推荐用于Linux)创建 systemd 服务文件: 在 /etc/systemd/system/ 目录下创建一个新的文件,例如 gunicorn.service。 文件内容如下:CodeCopy[Unit]Description=Gunicorn实例用于myappAfter=network.target[Service]User=你的用户名 # 替换成你的用户名Group=你的用户组 # 替换成你的用户组WorkingDirectory=/你的应用路径 # 替换成你的应用所在目录的绝对路径Environment="PATH=/你的虚拟环境路径/bin:$PATH" # 可选:如果你使用了虚拟环境ExecStart=/你的虚拟环境路径/bin/gunicorn --workers 3 --bind 0.0.0.0:9999 app:app如果你没有使用虚拟环境,请将上面一行替换为:ExecStart=/gunicorn的路径/gunicorn --workers 3 --bind 0.0.0.0:9999 app:appRestart=alwaysRestartSec=10[Install]WantedBy=multi-user.target请务必替换以下占位符:你的用户名: 你的Linux用户名。你的用户组: 你的Linux用户组。/你的应用路径: 包含你的Flask应用 (app.py) 文件的目录的绝对路径。例如 /home/user/myapp。/你的虚拟环境路径: 如果你使用了虚拟环境 (virtualenv),这是你的虚拟环境的 bin 目录的绝对路径。如果没有使用虚拟环境,请删除 Environment 行并修改 ExecStart 行。 /gunicorn的路径 指向gunicorn可执行文件的路径启用并启动服务: 保存文件后,执行以下命令:CodeCopysudo systemctl enable gunicorn.servicesudo systemctl start gunicorn.service检查状态: 使用以下命令检查 Gunicorn 是否正常运行:CodeCopysudo systemctl status gunicorn.service这将显示服务的运行状态,包括日志和错误信息。方法二:使用 Supervisor (跨平台)Supervisor 是一个更通用的进程监控工具,可在多种操作系统上运行。你需要先安装它(例如,在 Debian/Ubuntu 上使用 sudo apt-get install supervisor)。然后,你需要编辑 Supervisor 的配置文件(通常位于 /etc/supervisor/conf.d/gunicorn.conf),配置类似于 systemd 的例子,但语法不同。请参考 Supervisor 的文档了解具体的配置细节。重要注意事项:错误日志: Gunicorn 的日志对于调试至关重要。确保它们已正确配置并可访问。systemd 和 Supervisor 通常有记录服务输出的机制。进程管理: 在生产环境中,进程监控工具是必不可少的。它负责重启、优雅关闭和监控 Gunicorn 进程。安全性: 出于安全原因,请以非 root 用户运行 Gunicorn。虚拟环境: 强烈建议使用虚拟环境来隔离应用程序的依赖项。请仔细检查所有路径和用户名是否正确。选择 systemd 或 Supervisor 中的一种方法,不要同时使用两者。 在 Linux 系统上,通常推荐使用 systemd,因为它与操作系统集成得更好。 如果还有问题,请提供你的操作系统类型和 app.py 文件所在的目录。
-
优化 这段代码主要问题在于重复代码过多,以及路由处理方式不够优雅。 soft、device、wuhan 三个路由几乎完全相同,只是IP白名单和部分PM列表不同。gantt相关的路由也存在大量重复。 此外,错误处理可以更完善。以下提供优化方案:重构 IP 白名单:将 ip_whitelist 改为更易于管理的结构,例如字典嵌套列表:ip_whitelist = { 'soft': [ ('孔鲁文', "172.16.33.191"), ('李嘉政', "172.16.27.248"), # ... ], 'device': [ ('孔鲁文', "172.16.33.191"), # ... ], # ... }这样可以简化IP校验逻辑。创建辅助函数:创建辅助函数来处理重复的逻辑,例如:def process_project_data(ip_list, pm_list, remove_projects, is_normal): """处理项目数据,用于 soft, device, wuhan 路由""" removeTemoList = [f" name <> '{project}'" for project in remove_projects] removeProject = 'AND'.join(removeTemoList) joinTemp = [f" PmUserId = '{pm_id}'" for pm_name, pm_id, enabled in pm_list if enabled] PM = 'OR'.join(joinTemp) if joinTemp else "1=0" #避免空字符串导致错误 tempDatajson = { 'Normal': { 'count': None, 'DetailedList': SerachProject(PM, removeProject, True) }, 'over': { 'count': None, 'DetailedList': SerachProject(PM, removeProject, False) } } return render_template('base.html', tempDatajson=tempDatajson) # 创建一个 base.html 模板 def check_ip_and_auth(ip, ip_list, route_name): """检查IP地址和权限""" if ip in [ip_addr for _, ip_addr in ip_list]: whiteKeyName = [name for name, ip_addr in ip_list if ip_addr == ip][0] logger.info(f'{whiteKeyName} | {ip} 访问/{route_name}') return True else: logger.info(f'未授权 | {ip} 访问/{route_name}') return False def auth_required(func): """装饰器,用于检查权限""" def wrapper(*args, **kwargs): ip = request.remote_addr if not check_ip_and_auth(ip, ip_whitelist[kwargs['route_name']], kwargs['route_name']): return render_template("AuthFailed.html") return func(*args, **kwargs) return wrapper使用装饰器简化路由:使用装饰器 auth_required 来简化路由的权限检查:@app.route('/device', methods=['GET', 'POST']) @auth_required def device(): return process_project_data(ip_whitelist['device'], device_pm_list, remove_projects, True) @app.route('/soft', methods=['GET', 'POST']) @auth_required def soft(): return process_project_data(ip_whitelist['soft'], soft_pm_list, remove_projects, True) @app.route('/wuhan', methods=['GET', 'POST']) @auth_required def wuhan(): return process_project_data(ip_whitelist['wuhan'], wuhan_pm_list, remove_projects, True)你需要定义 device_pm_list, soft_pm_list, wuhan_pm_list 和 remove_projects 变量。重构 Gantt 路由:gantt 相关的路由也存在大量重复,可以提取公共部分:def handle_gantt(redis_name, pm_list, statement, template_name): today = datetime.now().strftime("%Y-%m-%d") redis_name = f'{redis_name}_{today}' try: random_string = request.args.get('token') if random_string == settings.gantt_tokens[template_name]: # 将token放到settings中 tempDatajson = project_gantt_public(redis_name, pm_list, statement) return render_template(template_name, tempDatajson=tempDatajson, today=today) else: return render_template("AuthFailed.html") except Exception as e: print(f"Error in gantt(): {e}") return "重新请求尝试" @app.route('/gantt', methods=['GET', 'POST']) def project_gantt_all_in_one(): return handle_gantt('project_gantt', ['李嘉政', '王清臣', ...], '', 'gantt.html') @app.route('/gantt_huishiyun', methods=['GET', 'POST']) def project_gantt_huishiyun(): return handle_gantt('project_gantt_huishiyun', ['李嘉政'], " AND a.ProjectBaseName NOT LIKE '%平台软件日常支撑(2024)%'", 'gantt.html') # ... 其他 Gantt 路由类似处理 ...在 settings.py 中定义 gantt_tokens 字典来存储每个 Gantt 路由的 token。改进错误处理:使用 Flask 的 errorhandler 装饰器来处理异常,提供更友好的错误页面。定时任务:定时任务部分代码可以优化,例如使用更简洁的数据库查询和数据处理方式。 可以考虑使用更强大的数据库ORM框架(如SQLAlchemy)来简化数据库操作。代码规范:使用更具描述性的变量名。保持代码缩进一致。添加必要的注释。总而言之,通过重构、提取公共方法、使用装饰器和改进错误处理,可以显著提高代码的可读性、可维护性和可扩展性。 记住,代码优化是一个迭代的过程,需要逐步改进。 我提供的方案是一个起点,你可以根据实际情况进行调整和完善。 你需要根据自己的需求创建 base.html 模板以及其他必要的修改。 也请确保你的 settings.py 文件包含了必要的配置信息。提供一个更结构化、更易于维护的代码框架,你需要根据你的实际环境和数据库配置进行调整。settings.py: import os # 数据库配置 DATABASE_URL = os.environ.get('DATABASE_URL') or '你的数据库连接字符串' # Redis 配置 REDIS_HOST = '192.168.10.100' REDIS_PORT = 6379 REDIS_PASSWORD = 'lijiazheng' REDIS_DB = 0 # 日志文件路径 LOG_FILE = '/home/bugsSerachZentao/logfile.log' LOG_MAX_BYTES = 1e6 LOG_BACKUP_COUNT = 3 # Gantt token gantt_tokens = { 'gantt.html': 'AoVv9Pba3sGjZoGEMjKgs6Bhaw29AaZnzMsEQdwHyqmWY_aio', 'gantt.html': 'N2ALqcECzjiZv9N6kJYBPBW9EJMNHVqL9QvtXTrCdZrmP_lijzh', 'gantt.html': '65KEq8sgQGUK8TQiUCB2MzZJjnlK7TVVevE8TZqk4WVBv_wqc', 'gantt.html': 'RaqWTAGqke46WHdmRep6N9g3fuGxQDPnjE973H7mCaYST_lcy', 'gantt.html': 'or8Alc3NZt9jx5fR79GFQdWrsDAqZDuCldAX4pDgimG73_platform', 'gantt.html': 'Qqu9w3fhJQfWd82U23Vpf8AoVUViYMevdexqQHC3FqERT_testing', 'test.html': 'test_46QYcgwBmmqAkRWL95VkH6aasd7WsYziQiChdWv4f3LbNcsfNGduudyDrgW5uUaV_test', 'iorz.html': '^gwUSSNwzUoRhgg7CZwSUQQUDiWG4XxZqT526DUgaaZhjb94Y95tTUz3w%%oc', 'ptyf.html': '^gwUSSNwzUoRhgg7CZwSUQQUDiWG4XxZqT526DUgaaZhjb94Y95tTUz3w%%oa', 'beziquePlus.html': 'V98cD8H7CZwSUQQUDiWG4XxZqT526DUgHGkHb94Y95t6Wz', } # ...其他配置... app.py: from flask import Flask, request, render_template, redirect from DBmodel.bugs import get_project_list # 假设这个模块存在 from DBmodel.info import zantao_project_baseInfo # 假设这个模块存在 import settings, warnings from logzero import logger, logfile from package.tools import Tools # 假设这个模块存在 from Model.project_info import SerachProject # 假设这个模块存在 from Model.timeLine import timelines # 假设这个模块存在 from Model.orz import orzs # 假设这个模块存在 from Model.ptyf import ptyfb # 假设这个模块存在 from Model.beziquePlus import bezique # 假设这个模块存在 from Model.project_gantt import gantt # 假设这个模块存在 from datetime import datetime from apscheduler.schedulers.background import BackgroundScheduler import redis, json from DBmodel.db_report_oa import MysqlDB # 假设这个模块存在 from decimal import Decimal from collections import defaultdict warnings.filterwarnings("ignore") # ... (IP 白名单部分,参考之前的重构方案) ... app = Flask(__name__) app.config.from_object(settings) redis_client = redis.StrictRedis(host=settings.REDIS_HOST, port=settings.REDIS_PORT, password=settings.REDIS_PASSWORD, db=settings.REDIS_DB) tools = Tools() logfile(settings.LOG_FILE, maxBytes=settings.LOG_MAX_BYTES, backupCount=settings.LOG_BACKUP_COUNT) # ... (辅助函数,参考之前的方案) ... # 路由 @app.route('/', methods=['GET', 'POST']) def index(): # ... (index 路由逻辑,参考之前的代码,简化重复部分) ... @app.route('/device', methods=['GET', 'POST']) @auth_required('device') def device(): return process_project_data(ip_whitelist['device'], device_pm_list, remove_projects, True, 'device.html') @app.route('/soft', methods=['GET', 'POST']) @auth_required('soft') def soft(): return process_project_data(ip_whitelist['soft'], soft_pm_list, remove_projects, True, 'soft.html') @app.route('/wuhan', methods=['GET', 'POST']) @auth_required('wuhan') def wuhan(): return process_project_data(ip_whitelist['wuhan'], wuhan_pm_list, remove_projects, True, 'wuhan.html') @app.route('/timeline', methods=['GET', 'POST']) def timeline(): tempDatajson = timelines() return render_template('timeline.html', tempDatajson=tempDatajson) @app.route('/orz', methods=['GET', 'POST']) @auth_required('jiaban') def orz(): tempDatajson = orzs() return render_template('orz.html', tempDatajson=tempDatajson) @app.route('/ptyf', methods=['GET', 'POST']) def ptyf(): # ... (ptyf 路由逻辑) ... @app.route('/beziquePlus', methods=['GET', 'POST']) def ptbeziquePlus(): # ... (beziquePlus 路由逻辑) ... @app.route('/gantt', methods=['GET', 'POST']) def project_gantt_all_in_one(): return handle_gantt('project_gantt', ['李嘉政', '王清臣', ...], '', 'gantt.html') @app.route('/gantt_huishiyun', methods=['GET', 'POST']) def project_gantt_huishiyun(): return handle_gantt('project_gantt_huishiyun', ['李嘉政'], " AND a.ProjectBaseName NOT LIKE '%平台软件日常支撑(2024)%'", 'gantt.html') # ... 其他 Gantt 路由 ... @app.route('/test', methods=['GET', 'POST']) def test(): return handle_gantt('project_gantt_huishiyun', ['李嘉政', '王清臣', ...], " AND a.ProjectBaseName NOT LIKE '%平台软件日常支撑(2024)%'", 'test.html') @app.route('/iorz', methods=['GET', 'POST']) @auth_required('jiaban') def iorz(): # ... (iorz 路由逻辑) ... # ... (错误处理) ... # ... (定时任务) ... if __name__ == '__main__': scheduler = BackgroundScheduler() scheduler.add_job(cron_OvertimeData, 'cron', hour=16, minute=37) scheduler.add_job(cron_getProjectTaskDetails, 'cron', hour=7, minute=30) scheduler.start() app.run(host='0.0.0.0', port=8080, debug=True) 其他模块 (Model, DBmodel 等):你需要根据你的实际情况完善这些模块。 确保你的数据库连接、数据模型以及其他依赖都正确配置。注意: 你需要替换占位符,例如数据库连接字符串,以及完善 device_pm_list, soft_pm_list, wuhan_pm_list, remove_projects 等变量,以及 handle_gantt 函数中的 pm_list 和 statement 参数。 还需要创建 base.html, device.html, soft.html, wuhan.html, gantt.html, test.html, iorz.html, timeline.html, ptyf.html, beziquePlus.html 等模板文件。 这个代码框架只是为了展示如何改进代码结构,你仍然需要根据你的实际需求进行调整和完善。 尤其要仔细检查数据库查询语句,避免SQL注入漏洞。 建议使用参数化查询来防止SQL注入。
-
Flask定时任务 方法一:使用 interval 参数 (每小时执行一次)from apscheduler.schedulers.background import BackgroundScheduler def cron_OvertimeData(): print('123') if __name__ == '__main__': scheduler = BackgroundScheduler() scheduler.add_job(cron_OvertimeData, 'interval', hours=1) # 每小时执行一次 scheduler.start() app.run(host='0.0.0.0', port=8080, debug=True)方法二:使用 cron 参数,更精确控制 (每小时的0分执行)from apscheduler.schedulers.background import BackgroundScheduler def cron_OvertimeData(): print('123') if __name__ == '__main__': scheduler = BackgroundScheduler() scheduler.add_job(cron_OvertimeData, 'cron', minute='0') # 每小时的0分执行 scheduler.start() app.run(host='0.0.0.0', port=8080, debug=True)方法三:结合 date 参数,设置起始时间和结束时间 (每小时执行一次,持续10小时)from apscheduler.schedulers.background import BackgroundScheduler from datetime import datetime, timedelta def cron_OvertimeData(): print('123') if __name__ == '__main__': scheduler = BackgroundScheduler() start_time = datetime.now() end_time = start_time + timedelta(hours=10) #运行10小时 scheduler.add_job(cron_OvertimeData, 'interval', hours=1, start_date=start_time, end_date=end_time) scheduler.start() app.run(host='0.0.0.0', port=8080, debug=True)重要提示: 这些代码片段都假设你已经安装了 APScheduler 库 (pip install apscheduler),并且你的代码中已经存在 app 对象 (例如,Flask 应用)。 你需要根据你的实际应用环境进行调整。 特别是 app.run() 部分,需要根据你的Web框架进行修改。 如果你的应用不是基于Flask,你需要替换成你的框架的运行方法。 另外,确保你的程序能够持续运行,否则定时任务将无法正常执行。 在生产环境中,建议使用更健壮的进程管理工具来保证程序的稳定运行。是的,APScheduler 提供了更丰富的功能,可以补充到之前的例子中,使定时任务更加强大和灵活。以下是一些补充用法:1. 任务参数传递:你可以向定时任务函数传递参数:from apscheduler.schedulers.background import BackgroundScheduler from datetime import datetime, timedelta def my_task(param1, param2): print(f"Task executed with parameters: {param1}, {param2}") if __name__ == '__main__': scheduler = BackgroundScheduler() scheduler.add_job(my_task, 'interval', hours=1, args=['hello', 123]) scheduler.start() # ... your app.run() ...2. 任务ID和替换:你可以为每个任务分配一个ID,方便管理和替换:from apscheduler.schedulers.background import BackgroundScheduler def my_task(): print("Task executed") if __name__ == '__main__': scheduler = BackgroundScheduler() job = scheduler.add_job(my_task, 'interval', hours=1, id='my_unique_job_id') # ... later, you can replace the job ... scheduler.remove_job('my_unique_job_id') new_job = scheduler.add_job(my_task, 'interval', hours=2, id='my_unique_job_id') scheduler.start() # ... your app.run() ...3. 任务的暂停和恢复:你可以暂停和恢复特定的任务:from apscheduler.schedulers.background import BackgroundScheduler def my_task(): print("Task executed") if __name__ == '__main__': scheduler = BackgroundScheduler() job = scheduler.add_job(my_task, 'interval', hours=1, id='my_job') # ... later, pause the job ... job.pause() # ... later, resume the job ... job.resume() scheduler.start() # ... your app.run() ...4. 错误处理:使用 misfire_grace_time 参数设置任务错过执行时间的容忍时间,避免因为短暂的延迟而导致任务丢失:from apscheduler.schedulers.background import BackgroundScheduler def my_task(): print("Task executed") if __name__ == '__main__': scheduler = BackgroundScheduler() scheduler.add_job(my_task, 'interval', hours=1, misfire_grace_time=60) # 允许延迟60秒 scheduler.start() # ... your app.run() ...5. 使用不同的调度器:除了 BackgroundScheduler,APScheduler 还提供了 BlockingScheduler (阻塞调度器,适合简单的脚本) 和 AsyncIOScheduler (异步调度器,适合异步环境)。 选择合适的调度器取决于你的应用架构。6. 监听事件:APScheduler 提供了事件监听机制,可以让你在任务执行前、执行后或出现错误时执行相应的操作:from apscheduler.schedulers.background import BackgroundScheduler from apscheduler.events import EVENT_JOB_EXECUTED, EVENT_JOB_ERROR def my_listener(event): if event.exception: print(f"Job {event.job_id} failed: {event.exception}") else: print(f"Job {event.job_id} executed successfully") if __name__ == '__main__': scheduler = BackgroundScheduler() scheduler.add_job(my_task, 'interval', hours=1, id='my_job') scheduler.add_listener(my_listener, EVENT_JOB_EXECUTED | EVENT_JOB_ERROR) scheduler.start() # ... your app.run() ...这些补充用法可以让你更精细地控制定时任务的执行,并处理各种异常情况。 选择哪些用法取决于你的具体需求。 记住查阅 APScheduler 的官方文档以获取更详细的信息和更多高级功能。
-
-
PDD 今日,我们聚焦拼多多平台的打假战略,尤其是其“假一赔十”的坚定承诺。然而,我们不能忽视一个严峻的现实:拼多多平台上确实存在着一定数量的假冒伪劣商品。更为令人愤慨的是,一些不良商家明知故犯,将假货伪装成正品销售,严重侵害了消费者的合法权益。图片接下来,让我们共同解析拼多多的“假一赔十”打假策略,以下几点关键信息请大家留心。在拼多多平台上,一些知名品牌和热销产品尤其值得我们关注:宝洁中国、舒肤佳香皂、欧普照明吸顶灯(含厨卫灯)、美孚机油、金士顿内存条、罗马仕充电宝、佳能单反相机、MBA生发液、贝亲奶瓶、雅鹿羽绒服、黑人牙膏、松下电冰箱等。需要特别提醒的是,拼多多现已全面推行“假一赔十”的保障承诺。若您不幸购买到假货,只需提供相关凭证,您将获得十倍现金无门槛券的补偿。因此,请大家在购物时保持高度警惕,确保自身权益不受侵害。图片那么,如何获取这个关键的凭证呢?对于上述提到的品牌,它们的官方都设有为消费者提供免费鉴定和凭证开具的服务。一旦你购买到疑似假货的商品,你可以直接联系商品品牌的官方客服。通常,他们会要求你提供商品的清晰照片,以便初步判断。在需要进一步验证的情况下,他们可能会建议你将商品寄送到他们的售后部门。凭借这份官方出具的凭证,你就能顺利地向拼多多平台提出赔偿申请。依据拼多多的“假一赔十”政策,你将获得所购商品金额十倍的现金无门槛券。举例来说,若你购买了一件价值200元的商品,一旦凭证验证通过,你将获得价值2000元的无门槛抵用券;若商品价值300元,则你将拥有价值3000元的无门槛券。过往经验表明,选购价格在200至400元区间的商品,有助于减少因金额过高可能引发的商家发货问题或后续快递困扰。图片那么,在拼多多上如何有效辨别假货呢?一个简单的方法是通过价格和卖家信息来判断。一般来说,若商品标价远低于官方指导价,并且非官方店铺出售,那么这些商品很可能存在质量问题。特别需要警惕的是那些详情页上标注“假一赔十”但店铺并非官方授权的商品。在售后部门的专业鉴定下,如果商品被确认为假货,官方将为你出具一份鉴定为假的凭证。这份凭证将成为你申请“假一赔十”的重要依据。要找到这些商品的链接,其实很简单。因平台限制我已整理好放在微信,免费添加领取:TY8668666。直接在拼多多上搜索“欧普吸顶灯”或“欧普厨房吸顶灯”等关键词,就能找到众多相关商品。我尤其推荐尝试搜索“欧普照明灯”,因为这类商品在市场上较为热门,容易找到潜在的假货链接。记住,购买时要仔细甄别,确保自己的权益不受损害。整个流程:一、找疑似假货链接:依据价格差判断。避免官方和百亿补贴店铺,选择第三方个人店。二、购买商品:一次性购买200~350元商品。三、拍摄开箱视频:记录开箱过程,以防商家争议。图片四、联系品牌方获取凭证:访问品牌官网或使用其他官方渠道。按品牌方要求鉴定货物。五、获取鉴定凭证:确定商品为假后,获得品牌方出具的凭证。六、联系拼多多客服:拨打客服热线021-5339-5288。按110或520转人工客服。七、向客服说明情况:陈述购买物品为假货,并提供使用体验不佳的证据。提及已联系品牌方并获得鉴定结果。拿到了凭证(鉴定书)证明商品为假货后,可以按照以下流程进行投诉:八、联系拼多多客服:拨打客服热线投诉,强调官方承诺的“假一赔十”政策。表达对假货的愤怒,要求赔偿并严肃处理。图片九、上传凭证并坚持赔偿要求:客服处理时,按要求上传凭证。如遇客服推脱,重申要求十倍赔偿。十、寄送商品进行鉴定并等待赔偿:根据提示,将商品寄送到拼多多上海总部进行鉴定。等待约十天后,抵用券将到账,可用于购物或套现。要求:拼多多账号需注册超过2个月,无官方电话记录,最好有购物记录,正常使用即可参与。事先声明:(只是做讲解 并不做推荐 个人文章仅供参考 做出违法的事情于本人无关不负任何责任)上述思路也是算最简单的,现在很多小白都已经大概掌握
-
-
-
-
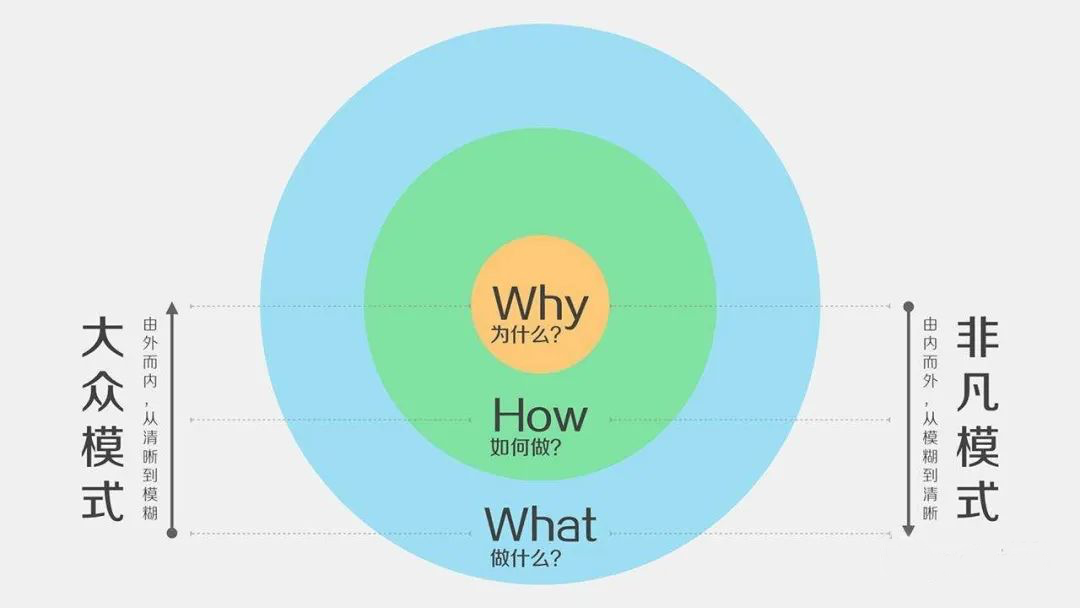
让你看透世界的8个底层逻辑 什么是底层逻辑?简单的说就是思考问题和解决问题的方法。思维层次越高,你的价值就越高;底层逻辑越坚固,解决问题的能力越强,发展机会就越多,成就也就越大。一句话:他能让你能够1秒钟看透问题本质。接下来我会带你探寻下8个让你变强的底层逻辑。一、自我GPS逻辑顾名思义要给自己一个准确的定位。你的定位是什么?首先弄清楚三个问题:第一,我是谁?第二,我能干什么?第三,我应该怎么干?之前招聘了一位程序员,来公司没几天,就送了我他家的茶叶,我也没太放心上。过了一阵子,又给我送了他自己家酿的酒。当然我立即看出来他的动机,我没有和他兜圈子,直接告诉他:“你的工作经验比较丰富,你的能力也还不错,但是东西就不要送了,拿回去吧,以后我也不会收了。你现在要做的就是把工作做好,严格要求自己,踏踏实实的把业务能力提升上去。可以吗?”他爽快的答应了。我对那位新员工说的话,主要目的就是想告诉他,你可以通过走后门获得小成功,但是你永远获得不了大成功。除了你自己,没人是你一生的依靠。送给大家第一句话:你是你最大的后台。之前有个粉丝问我“袁总,怎样才能最快的速度成功?”成功不是让大风把你吹上去,是你凿山为梯一步步爬上去的。做好信心定位,也要做好思想准备。被称为“管理之圣”的稻盛和夫在《干法》一书中说过四句话:不断树立高目标;付出不亚于任何人的努力;不要有感性的烦恼;严酷地锻炼自己。总结起来,就是要针对自己做好信心的定位,也要做好吃苦的思想准备,然后努力挖掘自己的潜力,逐步锻炼和提升能力。信心是第一步,吃苦是第二步,最后一步才是成就自我。从来没有捷径,必须循序渐进。所以,平步青云从来没有什么捷径,如果有的话,那它的价值也就不大了。送给大家第二句话:别总梦想一步登天。二、结果逻辑在优化工作的底层逻辑时,任何时候都十分重要的一条标准就是:无论做什么都要用结果去落实。结果总是第一位的,做事有始有终,用最终的成果说话。《创造卓越》一书的著名学者席尔瓦说过一段话:“在任何一个能和对手博弈的场合,胜利总是属于在思想上、计划上以及行动上比对手高出一筹的一方。”剖析这段话,席尔瓦的重点是——最能体现人的综合素质的是他的思想、计划及行动所创造的效果 。不管他是怎么想的,都要先出了效果再谈,否则就是空中楼阁。打个比方说,小明可能是一个很有想法的员工,她的创造力卓越,说起方案来头头是道,但这只能说明她的思想和计划上是优秀的。我表示赞赏,却不能认可。如果拿不出同样优秀的落地成果,他就称不上卓越,对公司而言在利益的分配上便没有他的一席之地。所以,在工作和利益之间起到连接作用的不是大脑中的思维,是行为结果。作为员工一定要勇于主动和优先地做事,不仅把工作做完,还要做得漂亮。当你能够在老板过问之前就将一个完美结果准备好的时候,你想要的利益自然就会主动找上门来。三、学习逻辑给大家讲一个真实我身边的故事。我的一个室友,是个温州人。大家都知道温州人擅长做生意。我这个室友天生就是做生意的料,而且极具领导天赋。我们组团打游戏时,他的指挥,控场能力就表现的淋漓尽致。大学毕业后,我选择了就业,而他选择了读自己学校的研究生。研究生期间他一直做着倒卖鞋子生意,我们都不以为意,认为这种小把戏上不了台面。最终结果是啪啪的打我的脸。研究生毕业后的他,找了一家公司实习,只干了半个月就辞职,创业卖鞋了。经过这么多年的经营,今年年初时候,跟他聊天,他去年收入已经达到了400万。悄悄的将座驾从e300L换成了s350了,还取了一个漂亮老婆,走向人生巅峰。讲这个故事,主要是想说:即便我已经算是同龄人当中混得不错的了,但是还有我身边还是有比我强很多的人存在,所以你还有什么理由不努力。努力的一个重要手段就是学习。记住:你可以拒绝学习,但你的竞争对手不会。过去的经验对我们来说既是资产,也是负债。未来的学习对我们来说既是投入,同时也是无比宝贵的资产。在过去能让你成功的经验如果今天不通过学习加以改进,现在和未来很可能便会成为你失败的原因。对手是不等人的,你必须时刻不停地学习,才能跟上强大对手的步伐。四、团队逻辑“大家强,你才会真的强。”这句话的核心讲的便是人在工作中要有团队精神。在团队的底层逻辑中,互相协作、彼此支援是将工作做好的坚固基础。不具备这种精神,你在一支团队中便很难立足,也很难实现自己的目标。纵观那些优秀的大公司,他们招聘和培训时对人才的要求除了能力,就是要有团队精神。要知道,懂得热爱同事,帮助同事,才能最终帮到自己,帮到公司。帮忙,也是一种合作式的学习。帮同事的忙,其实就是自主学习的一种形式,它在工作中是一种新型的学习方式。同事的工作遇到了问题,即便没有主动开口,你也要看看有没有可以伸手相助的地方。特别是你们各自负责的环节彼此影响时,更要有这种主动帮忙的精神,在协助他的同时了解自己不熟悉的领域,提高自己的见识。这对你的未来是大有好处的。帮这个忙不仅不会让你受损,反而对你大有裨益。有的人很自私,在工作中从不帮助别人,对同事的困难冷眼旁观,乃至看笑话,于是别人也不帮他,遇到问题时便两败俱伤。只有采取利人利己的双赢模式,才能促使我们在工作中不断地寻求双方和多方都获利的状态。有一句名言是这么说的:真正优秀的人将团队看作是合作的舞台,而不是非此即彼的竞技场 。五、态度逻辑在工作中会遇到各种各样的问题和困难,我们需要主动地去寻找方法解决,而不是找借口回避。只要不是科研型世界大难题,都能找得到解决难题的方法。这就是我们常说的那句话:“办法总比困难多。”工作中态度永远大于天——没能力可以学,没办法可以想,但没态度的话一切都完了 。有良好的态度,有积极想做好的愿望,就能在职场成功地发展,取得公司与同事的认可。那些面对问题能“知难而上”和积极寻找解决方案的人,才能将问题转变为机会,成长为负责而且高效的超一流工作者。六、能力逻辑提升能力,是我们在职场立足的根本。一个人的信心,归根结底是源于他的能力,而不是他的出身。在工作的底层逻辑中,能力是我们解决问题的根本,也是一条不可或缺的基础逻辑。工作中少了什么都行,就是不能少了能力。记住:好猎手不怕没肉吃。空有一身本事,怎么行?要露两手,让大家瞧一瞧。有能力,就要大胆表现出来。有能力但是不表现出来,等于没能力。如果你过于在意别人的看法和顾忌环境的氛围也会让人不自信,不敢抓住公开的机会,随之上司对你的信心就会越来越小,成功的机会也越来越远。机会就像漂亮的女孩,你不去追,就是在拱手让人。因此,一定要抓住机会,大胆地表现自己的能力,赢得公司的信任。因为只有表现出来的能力才叫价值 。七、责任逻辑责任心是你最大的安全符。有一个重大的预研项目,需要进行立项开工。找到组内的几个能力比较强的程序员,询问是否有人能够自告奋勇的承接这个项目。竟然哑口无言,过一阵子,小丁斩钉截铁的告诉我,他要承担这个项目。这个项目很有难度,他能够承担重任,就这件事他已经是做的非常好了。不管能不能成功,就已证明他是一个有责任心的员工,他在帮我解决难题,在帮公司清理麻烦,虽然这个项目不好做,我相信有我的支持,有公司其他人的配合,他的机会还是有的。即便最后做不好,我也不会批评他。最敢抓机会,最敢担责任,最敢接棘手的活,你在公司就已经有一只脚站到了成功的舞台上。一个富有责任心的强者,他必然敢于钻“矛盾窝”,擅长在“乱世”中抓机会,甚至是主动争取去办好“棘手的事”。对于这样的人,不管哪家公司都是会重用并且委以重任的。反之,有的人碰到有难度的工作就躲开,只想拣便宜,这样的人永远也成不了英雄,在工作中也很难有大的发展。八、沟通逻辑沟通是每一个技术人绕不开的技能,“别管我,我只想一个人安静写代码!”,这是不存在的。技术人大多数情况下并非是和计算机打交道而是人,本身写的代码就是给人看的。想要成为好的开发人员,领导心里的能力者,一定要学会正确的沟通。下面几点建议给到大家。1 丢掉自我为中心沟通是一种语言的表达。而表达背后其实反映的是一个人的思考方式。有些人说话喜欢用反问的方式。反问,也是一剂沟通的毒药。例如:你为什么会不知道呢?你难道不懂吗?你为什么不这样做?这样的问题,其实已经把你的建议藏在了问题中。这不是提问,这是把别人强行拉入到你的价值观念和判断体系,让人很不舒服。当别人启动防御机制时,距离吵架就不远了。当嘴仗开始时,距离答案就更远了。有些人的说话的方式是这样的:我说得这么明白,你怎么就是听不懂呢!我对你一片好心,你居然一点都不领情!我当然问心无愧,你应该好好反思自己!这些话语背后的模式,其实都暗藏着另一句话:我没有错。我苦口婆心,我勤勤恳恳,我任劳任怨,我没有错,都是别人的错。这种以自我为中心的沟通,应该戒掉。别人为什么不明白?不是别人不明白,而是你没有讲明白。你应该这么说会比较好:“我讲的足够清楚吗?”这句话的潜台词就是:“如果没有讲清楚是我的责任,我的问题。”这句话听起来会非常的舒服,没有很强的攻击性,情绪自然会好很多了。一个人会沟通,会说话,不仅仅是能清晰表达自己的意思,更是能让对方产生好的情绪。记住:不要反问,换位思考。2 保持谦虚在公司内,我们扮演者多个角色,有时候我们是下属,有时候我们是上级。你的下属可能会满心欢喜的完成了任务,告知你任务完成的喜讯。你的同事遇到问题,需要寻求你的帮助,满怀期待你的慷慨。很多老板都会冷冷冰冰的回了一句:“嗯,好”这句话是什么意思?背后的意思是啥?其实是想说,这点问题还需要我去帮你解决,这点任务完成了有什么好开心的,有什么难度吗?还有一点就是,“我现在真的很忙,不要来浪费我时间。”聪明很多人在心中都有一个 高大的ego,一个深深的自我,始终想和全世界证明自己的聪明,并且想尽一切办法告诉别人,我很聪明。所以请不要这么简单回复,尽量保持谦虚的态度“真棒,加油!”or“好的,请稍等,我这还需要几分钟”。既简单、谦虚,又不失礼貌。3 黄金思维黄金思维有三个层次——why、how、what。做任何事情都包含了这个黄金思维的三个层次。沟通是一种表达方式,当然也不例外。我们在沟通的时候,往往只可能关注一个点,what——就是干什么?但是,我们经常忽略了 why,为什么要做这件事,做这件事情的目的,有何价值。以及忽略了 how,如何做这件事。因此在职场沟通的时候,每当布置一个 what,你都要下意识地反应,前面还有一个大大的 why,后面还有一个大大的 how。 图片如果你是领导,把你的想法告诉你的下属,为什么要做这件事。没有任何一个人,希望在充满困惑的环境中工作。上图中,普通员工的思维模式,就是大众模式从外向内,从清晰到模糊。领导需要拥有非凡模式,从内向外,从模糊到清晰。黄金思维,这几乎是职场沟通最好的思维方式了。4 金字塔原则在工作中,不可避免的要向领导汇报。同样一件事,有的人三句话就能讲得清楚明白,而有些人半个小时,还没说到重点。汇报工作的时候,有的人5页ppt就能说服对方,要点就能把握,有的人,写了几十页,却被人问想表达什么。金字塔原则可以帮助到汇报困难户。基本结构是:结论先行,以上统下,归类分组,逻辑递进。先重要后次要,先总结后具体,先框架后细节,先结论后原因,先结果后过程,先论点后论据。例如:老板,我这个方案我觉得最优,第一,xxx,第二x,xxxx,第三xxxx。具体方案如下…。计划需要xx天,领导你觉得呢? 这个方案给到领导,有理有据、重点突出、思路清晰、层次分明、简单易懂,让领导有兴趣,能理解,记得住。总之两个字——满意!5 信息传递清楚了,就去干吧。你以为这样就行了吗?不行,没有deadline限制,没有清晰的目标时间限制,很容易拖延。这个时候,常常会设置一个“最后期限”(Deadline)。你以为最后deadline一天提交就行了吗?当然不行。deadline是最低要求,最好在这之前就完成。为了保持项目、任务的良性进展,需要时刻保持信息的畅通。主动的汇报自己的工作进展,让领导知道你正在干什么?干到什么程度了?有什么问题?需要什么资源?如果你是领导,每天能看到下属每天反馈进展,那种掌控的成就感,油然而生。所以在deadline之前,保持和领导的信息交流,这最好的沟通方式。上面的5点建议,丢掉自我为中心、保持谦虚、黄金思维、金字塔原则、信息传递,希望大家职业生涯中的能够沟通得更加优雅、从容。九、最后总结人与人之间的差距其实并不是由他表面的能力决定的,而是取决于他的底层逻辑。底层逻辑的优秀与平庸,塑造了他的生命格局与事业的成就。一个人不需要什么都会,也不需要豪言壮语。他只要能做到不断的学习和自我精进,更新提升自己的能力圈,在上面几个关键的方面优化底层逻辑,就能赢下人生中的大部分目标。以上共勉!
-
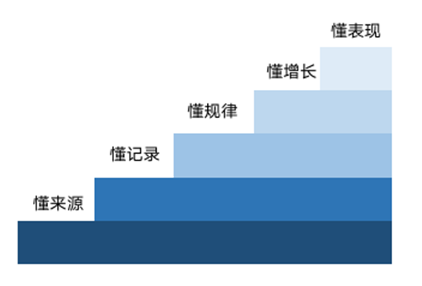
产品、运营、财务、项目经理等要求数据分析能力的岗位,到底要懂到什么程度? 懂数据,到底需要懂到什么地步?每一个层次都代表着一大类人群,大家可以对号入座。本文章适用这几类朋友:1、还没做过数据分析,希望通过数据分析提升业务分析能力2、野生产品,接触过数据分析,但总觉得学得不系统,没有方向3、已经在做数据分析,但是老板觉得我数据分析能力还比较差文章很长,建议收藏起来慢慢看,如果想节省时间,可以直接看目录。首先,来看下目录1、为何数据分析越来越重要?2、懂数据,至少要做到“五懂”1)懂来源:搞懂数据的来龙去脉2)懂记录:用数据记录业务变化3)懂规律:用数据理解业务规律4)懂增长:用数据驱动业务增长5)懂表现:用数据突出业绩亮点(每一个懂,都提供了具体的知识点/方法,帮助你在了解的同时快速掌握)一、为何数据分析能力越发重要?依我看,主要有两个方面:1、从宏观来讲1)经营环境变化:互联网快速普及,越来越多的人触“网”,增量的时代已经过去,存量时代来临,以往粗犷的经营模式难以为继,精细化、精益化经营成为主旋律。2)资本回归理智:烧钱、补贴,跑马、圈地,资本的疯狂,消费者的狂欢,已越发少见,当资本冷却下来,市场预算吃紧,再也不能不计成本的砸市场了,精打细算是常态。2、再微观到个人1)数据的复利效应个人通过数据分析提升决策的质量,获得更高的回报,再一次肯定了数据的价值。2)数据是最快树立信任感的方式先摆客观事实(数据),再讲个人观点,无论在什么场合,都更加具备说服力。专业性得到认可,自然也会有更多人愿意与你共事。3)数据是个人业绩最好的体现在大环境不好的时候,企业也更加注重价值贡献,并且实行末位淘汰机制,怎么对个人排名,相信业绩数据是一个更加合理的排名方式。既然数据分析这么重要,那么产品经理到底要懂到什么程度?二、懂数据,至少要做到“五懂”我把这“五懂”称之为升级打怪之路,每上一层,遇到的挑战更大,收获的回报也更大! 1、懂来源:搞懂数据的来龙去脉每天都在看的数据,你是否知道数据被分了哪几种类型?对应的口径是啥?在你面前的数据它经过了哪些系统?更新频率又如何?搞懂数据的来龙去脉是基础中的基础,也是后面通关的必备技能。为了帮助大家快速掌握技能,我按照问题类型,摘出必考问题和常见举例。(可收藏下来,时常翻阅)想搞懂数据来源,可以按照上表去反问自己,是否对这几类问题都了然于胸?如果是,恭喜你,通关成功!为方便大家理解,对于数据生成流程,附图如下(网图,侵删)2、懂记录:用数据记录业务变化这一层懂:是懂得如何提交数据需求,记录业务所需要的数据。最常提的数据需求有:前端埋点需求和业务报表需求。我们分别来讲讲,提交数据需求的规范和注意点。1)前端数据埋点需求什么是埋点:埋点,网页将用户的浏览、点击事件记录及上报到服务器的一套采集方法为什么要做埋点:埋点为后续的数据分析提供数据基础埋点数据的生成流程:按照规范输出埋点需求---网页采集用户数据---网页上报服务器---数据库清洗、加工、存储埋点数据---数据分析平台输出可视化报表怎么写埋点需求:手动埋点类,需要开发手动写代码去埋点,那么埋点需求中必备的字段如下,页面ID、区域ID、按钮ID属于开发定义。(可拿来即用)埋点需求注意点:注意按照用户体验流程逐个埋点,避免遗漏;埋点重在细致,尽可能把页面上涉及的操作事件都埋进2)数据报表需求数据报表需求,一般是先有业务整体数据报表的规划,再到具体的报表需求。段位低点的产品经理大部分不需要做数据指标规划的需求。提好数据报表需求的关键有三个:A 明确数据的类型、日常应用场景和使用频次,这样才能找准数据报表展示的位置B 明确每一个字段的定义,字段设定,要易于理解,较难理解的需要做好注释工作C 出需求前,首先确认上游数据是否支持,否则无法落地 3、懂规律:用数据理解业务规律写好数据需求是开始数据分析的第一步。当你有了数据之后,紧接着应该做什么呢?我认为是:分析数据,搞懂业务规律很多产品经理,都卡在这一层,无从下手。因为它一个综合的、多维度的分析。当然,它是需要方法的,掌握了,你也可以轻松驾驭。搞懂这个模块,我们从三个维度入手:意识、方法论、场景化分析纬度1:培养足够敏感的数据意识数据意识培养是一个持久战,所以最好的办法是从小细节做起。A 列学习清单,向前辈学习,开启意识培养第一步B 培养小习惯,享受意识红利1、利用好10分钟早餐时间,将关注的业务数据浏览一遍;2、核心数据手抄本:将高频用到的、非常关键的数据牢记于心,手工抄写,加深印象;3、活动数据备忘库:将活动的效果填入提前创建好的备忘库,用于时常查阅,提供思路;4、专题分析结论摘抄:将公司的数据分析师做的分析报告,摘抄关键结论,供随时查阅;5、简单数据处理,尽量少用计算器,锻炼自己的心算能力;纬度2:“望闻问切”的数据分析方法望闻问切来自中医的看病诊断,其实做业务数据分析也同样有用,尤其是遇到业务数据异常的时候。什么是望?望代表观察,观察业务的关键指标,用户行为层:流量(UV)、转化率(CR)、客单价;业务指标层,总交易金额、总交易笔数、总交易人数以及各业务模块的指标数据等,这些都是我们要观察的关键指标什么是闻?闻代表听闻,了解市场行情变化。整个经济大盘变化如何?是刺激消费还是吸引储蓄?楼下711最近在做哪几家银行的促销活动?竞争对手最近有没有上了什么新功能?什么是问?问代表询问,问问相关业务同事的动作。昨天是不是做了大量的消息推送?昨晚是不是上了新的产品功能?昨天是不是系统产生故障了?什么是切?切代表解析,深入了解主要异常的模块。异常往往是综合呈现的结果,主要那一块导致的异常,我们想要深入去解析它。比如,销售金额指标下降,那到底是流量少了,还是转化率小了?我们要深入解析它纬度3:场景化分析,快速进入分析心流天下武功唯快不破!当你还在苦思冥想的时候,高手已经把整个分析框架和思路都写好了,差异有时候真的很大。武器库装备本质的区别是啥?是基于实际问题的场景化分析能力。1)产品/运营都有哪些数据分析场景?2)每个场景的数据分析,类型和目的都有啥?3)万能的数据分析模版:不管什么场景都是可以套用的4、懂增长:用数据驱动业务增长做增长的方法论有很多,概况下来就是:上线最小可行化产品,根据北极星指标,不断实验测试,找到最能促进增长的因子,优化放大,从而获得指数级别的增长。这一套是增长黑客的玩法,不是所有公司都有条件玩的。不过,不用灰心。用数据驱动业务增长,其实不仅仅是增长黑客的特权,所有的产品都该具备该项能力。到了“懂增长”这一层,要比看懂业务规律更上一个层次。如何用数据驱动业务增长?我认为有三个方面:扩大效果、补足短板、降低损失。1)扩大效果产品用户增长不错,老板提出更高的要求,增长人数要翻一倍,怎么办?产品个性化推荐购率5%,到年底要达到8%,怎么办?这些工作中非常常见的问题,要是懂得数据分析,这里就能帮上大忙了。常规操作是:用公式法+拆解法。用数据分析思维,找到新的增长点。公式法:找到考核指标的组成公式,比如:用户数=下载人数转化率=A渠道下载人数转化率+B渠道下载人数转化率+...+X渠道下载人数转化率。拆解法:分析个渠道的下载量和转化率,找出转化率高的渠道,加大投放;找出转化率差的渠道,优化产品流程。2)补足短板通过数据分析及时发现,产品转化率比较差、用户点击率较少的功能,用漏斗分析的方法,逐层观察漏斗的转化情况,从而采取对应的产品策略:如调整页面结构、导航交互等,更好满足用户的需求。3)降低损失不仅如此,数据分析还能帮助企业减少资金损失/声誉损失,监控核心功能数据,,比如支付平台/优惠券平台。若超出异常阀值,按照严重程度,第一时间通过IM/邮件/短信/电话等渠道告知相关责任方,避免带来不可估量的后果。5、懂表现:用数据突出业绩亮点如果看完前面4个,你觉得已经到位的话,那你就大错特错了!前面4层是属于做好基本工作,第5层的重要意义在于:让你的工作脱颖而出,获得领导的认可。懂得用数据表现业绩亮点,永远是职场人的必修课。在大家工作都差不多的时候,如果用数据体现自己的与众不同和思考呢?这里给你三点建议,分别应对不同局势下的处理方式。1)业绩好强调过程项目过程的艰辛之处,或者是团队做了什么动作?做了什么测试?使得数据增长的不错,让领导相信增长并非偶然。2)业绩一般找局部亮点数据绝对值增长比较少或者数据比较小的时候,可以用百分比去描述效果;又或者把数据拆解来看,找其中增长得比较好的地方,分析下是否可以扩大效果。3)业绩差重点分析原因及对策处于逆境的时候,分析一定要深入!经受住领导的连环挑战:为什差?具体差在哪里?同比差了多少?这个阶段做了什么?数据如何?为啥没有效果?哪个环节做得不好?给予领导信心:下一步该计划怎么做?为什么这样做?预计带来多大的效果?什么时候做?当前进度如何?下次同步进展情况的时间是什么时候?上述的只是职场的冰山一角,数据用得好,如虎添翼;对数据没概念,寸步难行。在文章的最后在数据越发重要的今天,数据分析已经是产品技能包里必备的技能。希望大家通过我今天的分享,对产品搞懂数据有基本的认识。把“五懂”作为一个指引的灯塔,在修炼的路上,你我结伴前行!祝愿,人人都能成为数据分析师!
-
-
-
-
-
-